
Ne dites plus « ELK » mais « The Elastic Stack »
Il y a quelques temps déjà, nous vous avions présenté ce qu’on appelle « la pile ELK », dans un article dont le titre est « ELK : Trio de charme ElasticSearch, Logstash & Kibana ». Aujourd’hui, cette pile ELK n’existe plus! Elle a évolué pour devenir « Elastic Stack ». Analysons ce changement au travers des dernières nouveautés annoncées par les développeurs d’Elastic Stack.
Petits rappels
ELK signifie ElasticSearch, Logstash et Kibana. Il s’agit de coupler les 3 logiciels pour obtenir une solution d’analyse de log performante et complète. Les outils sont:
- ElasticSearch : moteur de stockage et d’indexation de documents et moteur de requête/d’analyse de ceux-ci
- Logstash : analyse, filtrage et découpage des logs pour les transformer en documents, parfaitement formatés notamment pour ElasticSearch
- Kibana : dashboard interactif et paramétrable permettant de visualiser les données stockées dans ElasticSearch
Ces outils libres sont développés par la même structure, la société Elastic, qui encadre le développement communautaire et propose des services complémentaires (support, formation, intégration et hébergement cloud).
« ELK », jusqu’à il y a peu, n’avait un sens qu’uniquement parce que ces outils s’associent parfaitement et l’on parlait de « pile ELK » par commodité : en réalité, il n’y avait pas de « produit ELK ».
Un(?) nouveau venu
Pour répondre à de nouveaux besoins, un (un seul?) nouvel outil développé par Elastic est apparu : Beats. Beats regroupe en fait plusieurs outils différents :
- PacketBeat : moniteur réseau
- TopBeat : moniteur des « tops » (les processus ayant consommé le plus de mémoire vive, de CPU, …)
- FileBeat : moniteur temps-réel des fichiers
- WinlogBeat : moniteur temps-réel des eventlog Windows
- LibBeat : une bibliothèque de fonctions (lib en anglais) spécialisée pour Beats
Les outils se marient parfaitement avec « la pile ELK » : les données collectées par Beats sont stockées dans ElasticSearch, peuvent être enrichies par LogStash et sont visualisées par Kibana. Ils méritent d’être liés à « la pile ELK ».
Un renommage d’abord pragmatique…
Un problème apparaît : ELK est déjà trop connoté et peu pensent à Beats lorsqu’ils parlent de « ELK » ou de « pile ELK ». Beats pourrait pâtir de ce point. Quelques questions se posent :
- comment intégrer le B de Beats dans ELK? Doit-on parler de BELK? Il n’est pas sûr que ce point est joué mais en français, cela sonne plutôt comme quelque chose de négatif (BELK? BEULK? beurk!). Sinon, on pourrait utiliser aussi ELKB… Un peu long non?
- comment intégrer les futurs produits? Elastic devra-t-elle trouver une lettre s’intégrant parfaitement avec ELKB ou BELK avant de trouver un nom commençant par cette lettre et représentant l’outil? Le département Marketing va avoir du boulot!
Non, il fallait trouver autre chose. Un nouveau nom pouvant intégrer tous les outils actuels et les prochains aussi. Et le nom de « The Elastic Stack » fut choisi.
… mais d’un véritable intérêt stratégique
« The Elastic Stack » sonne plutôt bien et à l’avantage de rappeler à la fois la base (ElasticSearch) mais aussi l’entreprise (Elastic) et indique qu’il s’agit d’une composition d’outils (le terme Stack). Le nom décrit parfaitement le produit tout en ouvrant la possibilité d’intégrer de futurs produits à cette stack.
Un autre intérêt stratégique est lié à ce changement de nom. Lorsqu’on compose des outils pour en faire une solution complète, un problème apparaît : la gestion des numéros de version et des incompatibilités entre les composants de cette sollution. Aujourd’hui, si l’on prend la « pile ELKB/BELK », nous avons :
- ElasticSearch 2.3.x
- Logstash 2.3.x
- Kibana 4.5.x
- Beats 1.2.x composé de :
- Winlogbeat 1.2.x
- Filebeat 1.2.x
- Topbeat 1.2.x
- Packetbeat 1.2.x
- LibBeats 1.2.x
Comment s’assurer que tous les produits sont compatibles entre-eux? D’un point de vue technique, c’est compliqué : il faut gérer une matrice de compatibilité qui doit être fournie par l’éditeur. L’éditeur doit faire des tests en faisant varier les versions de chaque composant. Les mises à jour doivent être bien documentées pour éviter qu’un utilisateur perde des données. La matrice de compatibilité doit être claire et compréhensible, sans erreur d’interprétation possible.
D’un point de vue marketing, c’est compliqué aussi! Toute la communication doit aussi être mise en œuvre pour que les utilisateurs et les clients suivent (correctement!) la matrice de compatibilité. Lorsqu’un client ou un utilisateur mettra à jour un composant qui sera incompatible avec tous les autres, c’est l’image des développeurs et de l’entreprise qui va en pâtir par les retours sur les forums utilisateurs, les articles de blog négatifs, les présentations lors des événements communautaires (salons, forums) et les bugs ouverts. Et ces retours négatifs risquent d’être très nombreux : les outils sont jeunes et évoluent très vite et le succès est grandissant.
D’où l’idée d’Elastic de coordonner les numéros de version : désormais il y aura un produit « The Elastic Stack » dans une version donnée et intégrant tous les outils, chaque outil ayant la même version majeure. La première version de « The Elastic Stack » sera la prochaine version, la version 5.0.0 et intégrera tous les produits dans la version 5.0.0. Ce qui sera plus simple pour tout le monde : clients, utilisateurs mais aussi développeurs et ingénieurs support d’Elastic!
Refonte graphique
Pour communiquer plus efficacement sur « The Elastic stack », la charte graphique des outils a été refondue lentement. Dorénavant, il y a une unicité graphique entre les outils concernant les logos :

Auparavant, les logos pouvaient être très différents :
![]()
Première version disponible
La première version alpha de « The Elastic Stack » est disponible en version 5.0.0 alpha 1. Bienvenu à « The Elastic Stack » et merci à « la pile ELK » pour les services rendus.
Read MoreLogstash 2.3.0 : forte amélioration des performances
Logstash est un outil de collecte, de traitement et de transport de données. Logstash est disponible en version 2.3.0 depuis le 30/03/2016 et cette nouvelle version apporte, en autres, une augmentation significative des performances.
Présentation rapide de Logstash
Logstash a pour but d’ingérer des logs (fichiers journaux des systèmes et applications) ou des messages (provenant de RabbitMQ par exemple), de les analyser (filtrer les messages inutiles, les découper, extraire l’information utile, les formater) puis de les stocker, généralement dans ElasticSearch pour être indexées. La force de Logstash est de pouvoir ingérer tout type de logs :
- des logs au format syslog : très répandus sur les systèmes GNU/Linux et Unix
- des logs en texte brut
- des logs Apache et Log4j
- des logs Windows Event Logs
- des messages au format JSON
- des messages passant par des files de messages (RabbitMQ, ZeroMQ)
- …
Bien entendu, vous pouvez étendre le système et faire ingérer vos propres formats. Une fois les messages ingérés, Logstash les filtre, prend des actions et/ou les formate pour les stocker dans ElasticSearch, MongoDB, Riak, …
Logstash évolue très rapidement et de nouvelles versions apportent souvent de nouveaux connecteurs, tant en entrée qu’en sortie.
Version 2.3.0 : forte amélioration des performances
La version 2.3.0 de Logstash est sortie le 30/03/2016 et cette version apporte une forte amélioration des performances. Elle se traduit par un traitement plus rapide des messages, une augmentation de la vitesse de traitement jusqu’à, dans certains cas, 79%. Cette augmentation est due à la ré-écriture en pure Java d’un composant de l’application, préalablement écrit en Ruby. L’équipe de développement de Logstash a fait des tests et a publié les résultats dont voici un résumé :
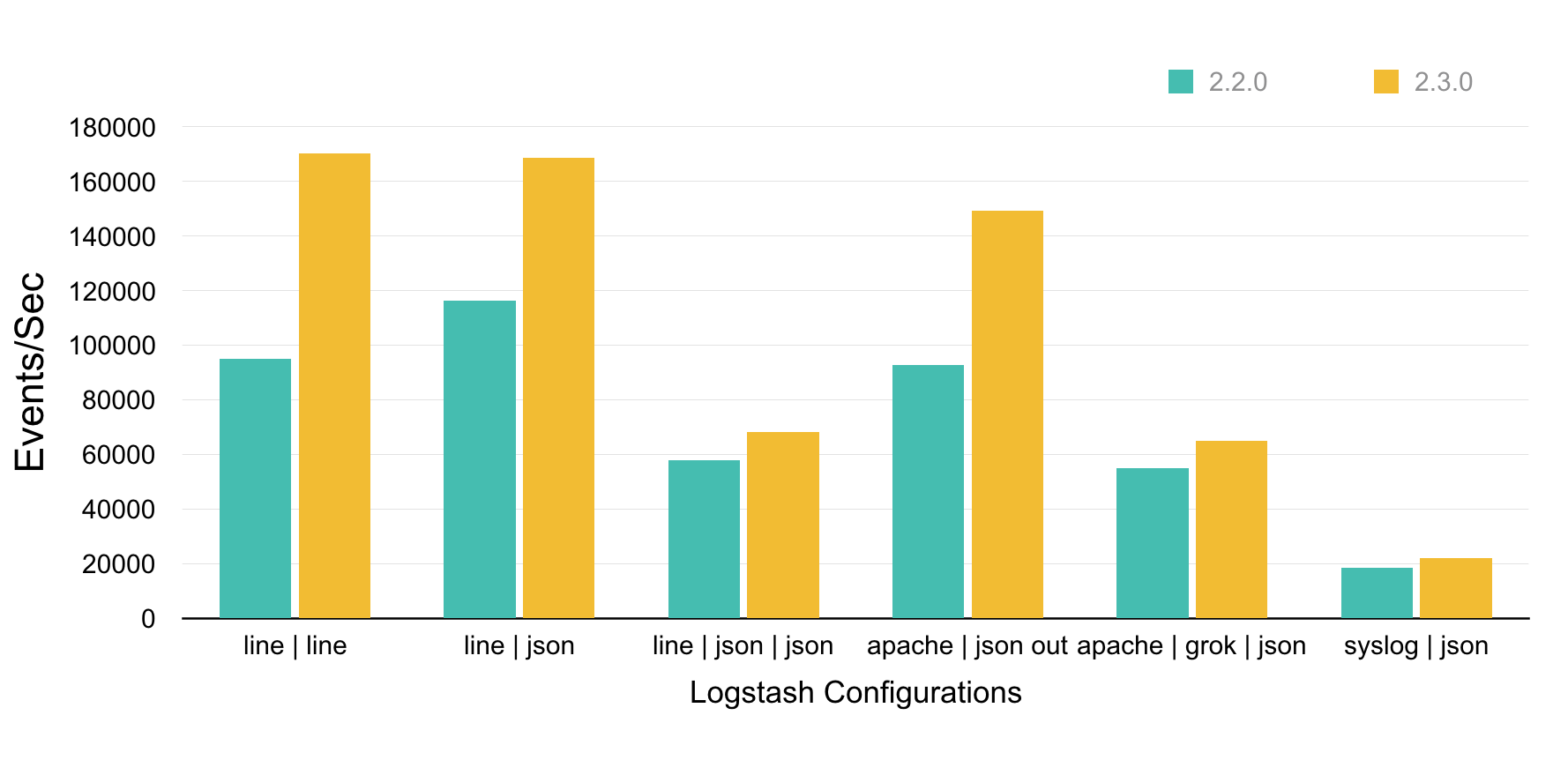
Lostash 2.3.0 : améliorations des performances diagramme
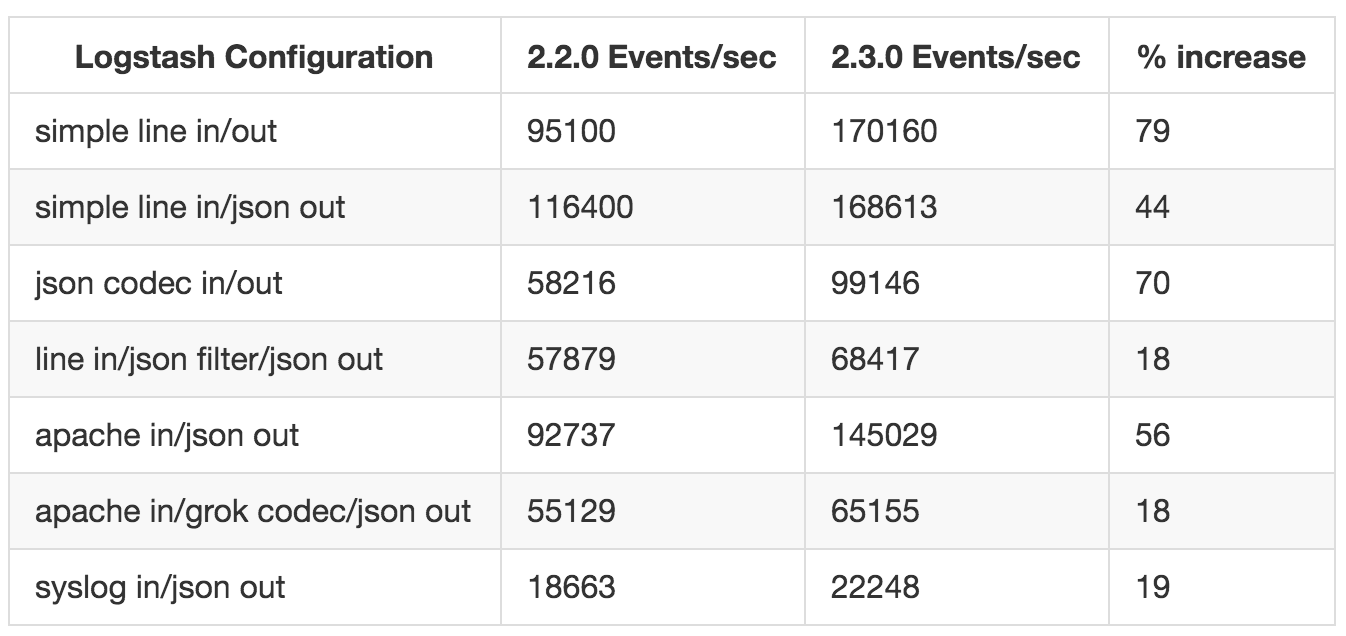
Lostash 2.3.0 améliorations des performances tableau
Relecture à chaud de la configuration
Cette version 2.3.0 introduit la relecture de la configuration à chaud. Cela permet de ne pas avoir à redémarrer le service lorsqu’un paramètre de la configuration est modifié : en effet, Logstash va vérifier régulièrement (toutes les 3 secondes, par défaut) si une modification a été faite sur les fichiers de configuration. Dans ce cas, il va relire les fichiers et adapter son comportement. Pratique lorsqu’on développe mais aussi lorsque la configuration est modifiée par des outils externes, en fonction de règles dynamiques : cela évite de redémarrer Logstash par un script.
Pour activer la relecture à chaud, il faut passer l’option --auto-reload lors du démarrage de Logstash.
Si jamais vous souhaitez maîtriser le moment où LogStash doit relire la configuration, il vous suffit de ne pas passer l’option --auto-reload et d’envoyer le signal SIGHUP au processus.
Comment faire suivre les messages Nagios vers logstash
Tout ceux qui ont utilisé un Nagios like un jour se sont retrouvés confrontés à ce problème.
Les logs de Nagios ne sont pas vraiment sympas à lire pour un humain et il est très difficile d’en sortir des statistiques sauf à écrire soi-même le « parser » qui va bien.
Alors pourquoi ne pas utiliser un logiciel qui en a plein justement des « parsers », à savoir Logstash ? Voici une approche possible parmi d’autres, enfin j’imagine. Ce sera aussi l’occasion de découvrir par l’exemple la nouvelle version de Kibana, quatrième du nom.
Read MoreELK : Trio de charme ElasticSearch, Logstash & Kibana
ElasticSearch a sortie récemment le projet portant le nom « Pile ELK« . Cette solution facilite l’installation du trio ElasticSearch, Logstash et Kibana. Vous avez maintenant à disposition les packages RPM & DEB pour pouvoir les installer en 5 minutes chrono ;).
Pour rappel, ElasticSearch est un puissant moteur de recherche utilisé par exemple par github, Sony, SoundCloud, Mozilla, Stackoverflow, IGN et bien d’autres encore. Orienté “document” (au sens NoSQL du terme), toutes les données sont stockées sous forme de documents JSON structurés. Tous les champs sont indexés par défaut, et tous les index peuvent être utilisés dans une même requête, pour retourner les résultats correspondant à une recherche à une vitesse impressionnante.
L’équipe du blog Wooster a réalisé un bon article servant de mise en bouche à l’apprentissage de la Pile ELK que vous pouvez lire à cette adresse : Introduction à ELK : Elasticsearch, Logstash et Kibana.
Sinon vous pouvez nous rendre visite au stand A44 au salon Solution Linux le 20 & 21 mai 2014 pour voir de quoi ça à l’air et constater la puissance de ce trio.
Bonne lecture & bon POC à vous 😉
Read MoreEnfin du nouveau dans la gestion des logs
Dans une époque qui deviendra peut-être lointaine, à part centraliser ses fichiers journaux aka logs via le protocole syslog (pour les fichiers à cette norme) et un bon vieux tail -f sur le résultat ou mieux, un multitail, arrosé d’un soupçon de scripts personnels, il n’y avait pas grand chose de possible en matière de centralisation, gestion (recherche, archivage) des fichiers journaux.