
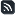
Comment faire suivre les messages Nagios vers logstash
Tout ceux qui ont utilisé un Nagios like un jour se sont retrouvés confrontés à ce problème.
Les logs de Nagios ne sont pas vraiment sympas à lire pour un humain et il est très difficile d’en sortir des statistiques sauf à écrire soi-même le « parser » qui va bien.
Alors pourquoi ne pas utiliser un logiciel qui en a plein justement des « parsers », à savoir Logstash ? Voici une approche possible parmi d’autres, enfin j’imagine. Ce sera aussi l’occasion de découvrir par l’exemple la nouvelle version de Kibana, quatrième du nom.
Le contexte
Par Nagios like, j’entends tout logiciel capable de produire des lignes de logs au « format » Nagios, ce qui en fait quelques uns.
[1430313027] SERVICE ALERT: localhost;SSH;CRITICAL;SOFT;3;connect to address 127.0.0.1 and port 22: Connection refused
[1430313164] EXTERNAL COMMAND: SCHEDULE_FORCED_SVC_CHECK;localhost;SSH;1430313161
Notez au passage le fameux timestamp pas vraiment sympa à utiliser au quotidien par un humain en train de lire ces lignes. À part jouer avec la commande date -r 1430313164 à chaque fois.
Les logiciels utilisés dans ce setup sont la désormais classique pile ELK, dans sa dernière version pour chacun des composants soit :
- Logstash 1.4.2
- Elasticsearch 1.5.2
- Kibana 4.0.2
Ainsi que Icinga 1.13.2 et le plugin Monitoring-Generator-TestConfig qui permet de générer une configuration Nagios automatiquement. il permet aussi d’avoir des retours variés sur les tests, bien pratique pour générer des événements Warning et autres Critical dont nous allons avoir besoin.
La configuration
Logstash possède un filtre Nagios tout prêt dans ces filtres Grok et c’est celui que nous allons utiliser.
Logstash
Le fichier de configuration proposée est le suivant :
input {
file {
type => "nagios"
path => "/usr/local/icinga/var/icinga.log"
}
}
filter {
if [type] == "nagios" {
grok {
match => { "message" => "%{NAGIOSLOGLINE}" }
}
date {
locale => en
match => ["nagios_epoch", "UNIX"]
}
}
}
output {
elasticsearch {
host => localhost
}
}
Rien de particulier à signaler sinon justement le filtre Grok réglé sur %{NAGIOSLOGLINE}.
Kibana
Passons du coup à Kibana pour par exemple compter le nombre d’incidents de production intervenus durant les X derniers jours/mois…
nagios_state:(WARNING OR CRITICAL) AND nagios_statelevel:(HARD)
Cette requête permet de retrouver parmi tous nos évenements Nagios ceux en état WARNING ou CRITICAL et dont l’état est fixé à HARD. Ainsi, nous ne comptons que les événements avérés, ceux pour lesquesl Nagios a épuisé le nombre de tentatives maximales.
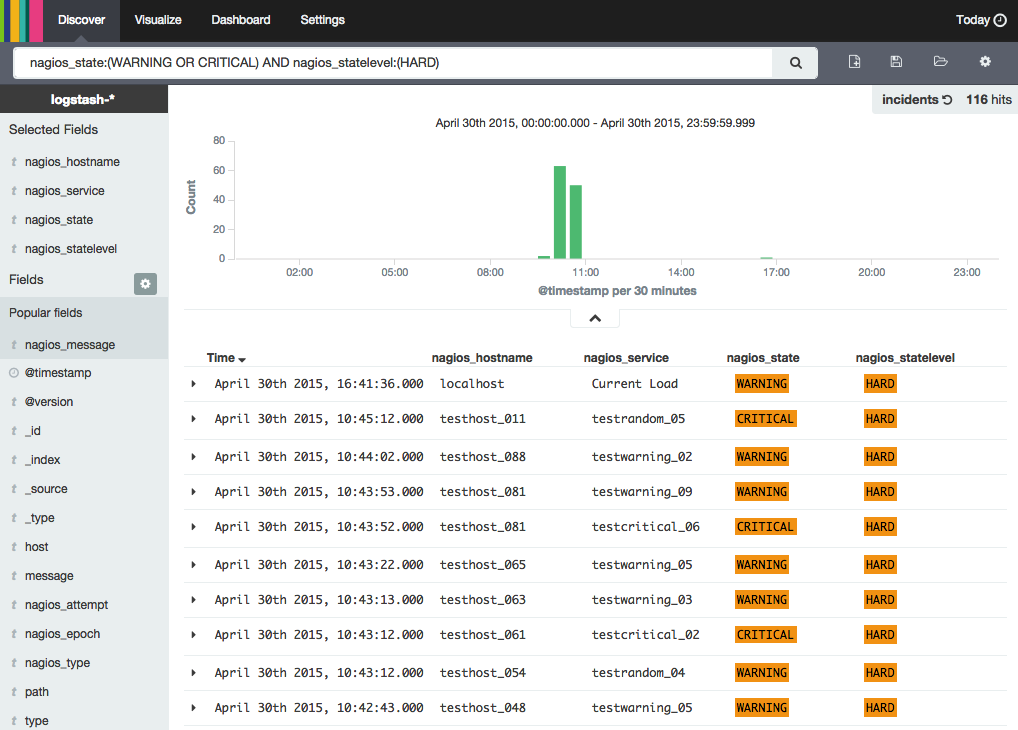
Après avoir enregistré cette recherche, je passe ensuite dans le module Visualize de Kibana et j’utilise deux types distincts de visualisation :
- Metrics
- Vertical bar chart
Arrêtons-nous sur le Vertical bar chart puisque Metrics est juste un compteur de l’ensemble des incidents qui ne demande pas d’explication.
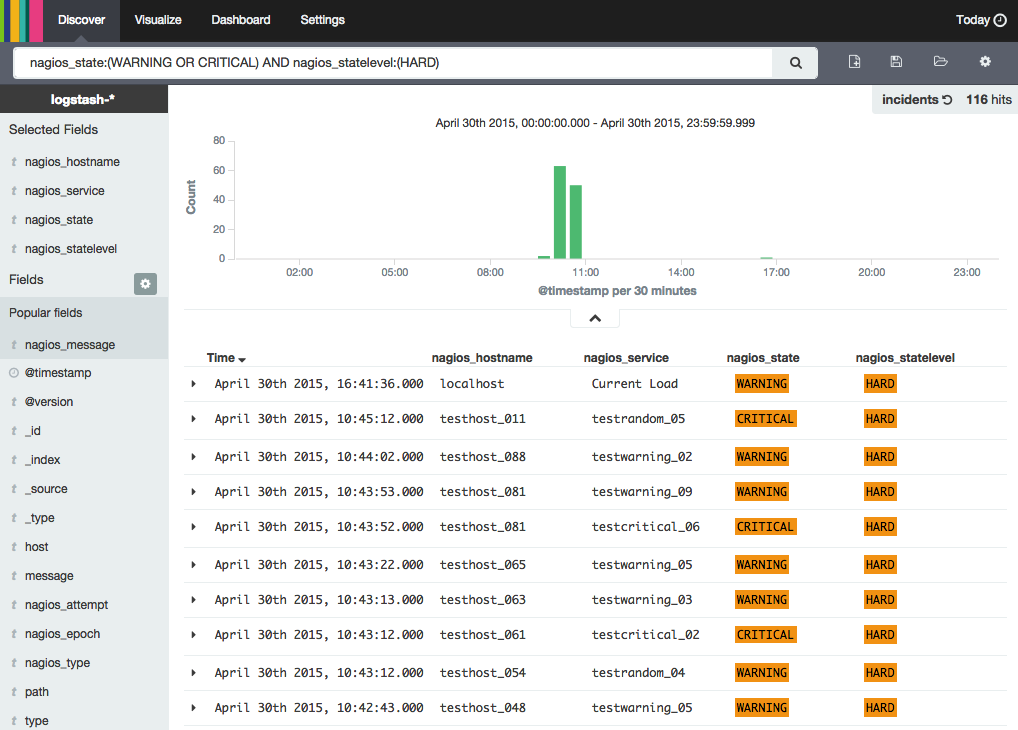
Deux choses à expliquer. La première est le fait d’utiliser la fonction Split Bars pour repartir en colonnes les incidents WARNING et les CRITICAL. Il suffit à chaque fois de « rejouer » la bonne requête sur nos données.
La deuxième est la fonction Bar Mode que j’ai choisi en grouped car je ne suis pas fan des aires stackées, que je trouve peu pratique pour comparer le nombre de chaque incident. J’enregistre chacune de ces visualisations et je passe à la dernière étape : le Dashboard.
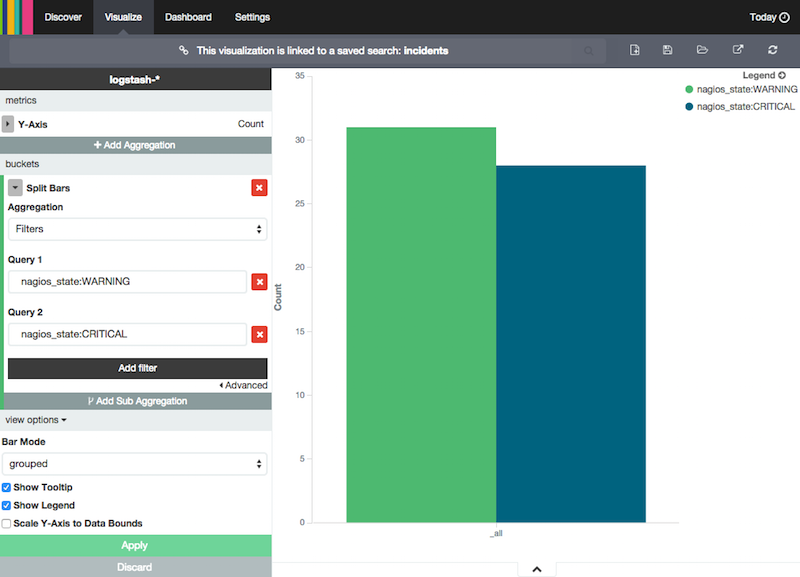
Je n’ai pas la prétention d’avoir fait au mieux, découvrant moi-même Kibana 4. À vous d’affiner sur cette base bien sûr !
Au final
D’aucuns pourront dire que j’ai un peu sorti le bazooka pour un problème somme toute mineure mais à partir du moment ou vous utilisez déjà ce setup, pourquoi pas ? Rien de plus à installer et juste un peu de configuration pour au contraire voir arriver dans la même interface vos logs Apache, Nginx, Rsyslog… et donc désormais Nagios. Et puis si au passage, je vous ai donné envie d’essayer Kibana 4, c’est tout bénéfice !
No Comments
Trackbacks/Pingbacks