
Meetup Paris Monitoring #6 : interview du sponsor Ikoula
Le 6e Meetup Paris Monitoring a eu lieu le mercredi 18 mai et avait pour thème « la collecte, le stockage et la manipulation de métriques/séries temporelles ». Cet événement était sponsorisé par Logmatic.io et Ikoula déjà bien connu des participants car c’est la deuxième fois qu’ils sponsorisaient un meetup Paris Monitoring, le premier étant un crossover Paris Monitoring / DevOps.
À cette occasion, nous en avons profité pour interviewer Jules-Henri Gavetti, le fondateur d’Ikoula, hébergeur français bien connu afin qu’il nous présente sa société et ses services proposés mais aussi les raisons qui font qu’Ikoula sponsorise le Meetup Paris Monitoring. Jules-Henri nous parle aussi des outils de supervision utilisés par Ikoula.
Vous pouvez télécharger directement les fichiers MP3 ou OGG pour une écoute offline en cliquant sur les icônes correspondantes.
![]()
![]()
Read More
Meetup Paris Zabbix #1 avec Alexei Vladishev le 23 juin 2016 chez Blablacar
Le groupe Meetup Paris Monitoring s’étend et propose un Meetup Paris Zabbix UG (User Group) le 23 juin 2016. Fait marquant de ce meetup, la participation d’Alexei Vladishev, créateur de Zabbix, logiciel libre de supervision et de monitoring, fondateur et CEO de Zabbix LLC, la société éditrice de Zabbix. Meetup à ne pas manquer si vous êtes fan de Zabbix!
Le meetup aura lieu le jeudi 23 juin 2016, dans les locaux de la société Blablacar, sponsor de l’événement mais aussi utilisateur de Zabbix. Pour rappel, un cas d’utilisation de Zabbix avait déjà été réalisé par Blablacar lors du premier meetup Paris Monitoring en juin 2015 :
« 23k métriques & 6,5k alertes, 300 tests par seconde avec Zabbix: comment fait-on chez BlaBlaCar ? »
Par Jean Baptiste Favre / @jbfavre / http://www.jbfavre.org
À noter que vous pouvez proposer des sujets si vous souhaitez faire un retour utilisateur de Zabbix.
Pensez à vous inscrire sur le site pour participer à l’événement.
Correctif : le meetup aura bien lieu le jeudi 23 juin (et non le 26 comme mentionné précédemment).
Read MoreNe dites plus « ELK » mais « The Elastic Stack »
Il y a quelques temps déjà, nous vous avions présenté ce qu’on appelle « la pile ELK », dans un article dont le titre est « ELK : Trio de charme ElasticSearch, Logstash & Kibana ». Aujourd’hui, cette pile ELK n’existe plus! Elle a évolué pour devenir « Elastic Stack ». Analysons ce changement au travers des dernières nouveautés annoncées par les développeurs d’Elastic Stack.
Petits rappels
ELK signifie ElasticSearch, Logstash et Kibana. Il s’agit de coupler les 3 logiciels pour obtenir une solution d’analyse de log performante et complète. Les outils sont:
- ElasticSearch : moteur de stockage et d’indexation de documents et moteur de requête/d’analyse de ceux-ci
- Logstash : analyse, filtrage et découpage des logs pour les transformer en documents, parfaitement formatés notamment pour ElasticSearch
- Kibana : dashboard interactif et paramétrable permettant de visualiser les données stockées dans ElasticSearch
Ces outils libres sont développés par la même structure, la société Elastic, qui encadre le développement communautaire et propose des services complémentaires (support, formation, intégration et hébergement cloud).
« ELK », jusqu’à il y a peu, n’avait un sens qu’uniquement parce que ces outils s’associent parfaitement et l’on parlait de « pile ELK » par commodité : en réalité, il n’y avait pas de « produit ELK ».
Un(?) nouveau venu
Pour répondre à de nouveaux besoins, un (un seul?) nouvel outil développé par Elastic est apparu : Beats. Beats regroupe en fait plusieurs outils différents :
- PacketBeat : moniteur réseau
- TopBeat : moniteur des « tops » (les processus ayant consommé le plus de mémoire vive, de CPU, …)
- FileBeat : moniteur temps-réel des fichiers
- WinlogBeat : moniteur temps-réel des eventlog Windows
- LibBeat : une bibliothèque de fonctions (lib en anglais) spécialisée pour Beats
Les outils se marient parfaitement avec « la pile ELK » : les données collectées par Beats sont stockées dans ElasticSearch, peuvent être enrichies par LogStash et sont visualisées par Kibana. Ils méritent d’être liés à « la pile ELK ».
Un renommage d’abord pragmatique…
Un problème apparaît : ELK est déjà trop connoté et peu pensent à Beats lorsqu’ils parlent de « ELK » ou de « pile ELK ». Beats pourrait pâtir de ce point. Quelques questions se posent :
- comment intégrer le B de Beats dans ELK? Doit-on parler de BELK? Il n’est pas sûr que ce point est joué mais en français, cela sonne plutôt comme quelque chose de négatif (BELK? BEULK? beurk!). Sinon, on pourrait utiliser aussi ELKB… Un peu long non?
- comment intégrer les futurs produits? Elastic devra-t-elle trouver une lettre s’intégrant parfaitement avec ELKB ou BELK avant de trouver un nom commençant par cette lettre et représentant l’outil? Le département Marketing va avoir du boulot!
Non, il fallait trouver autre chose. Un nouveau nom pouvant intégrer tous les outils actuels et les prochains aussi. Et le nom de « The Elastic Stack » fut choisi.
… mais d’un véritable intérêt stratégique
« The Elastic Stack » sonne plutôt bien et à l’avantage de rappeler à la fois la base (ElasticSearch) mais aussi l’entreprise (Elastic) et indique qu’il s’agit d’une composition d’outils (le terme Stack). Le nom décrit parfaitement le produit tout en ouvrant la possibilité d’intégrer de futurs produits à cette stack.
Un autre intérêt stratégique est lié à ce changement de nom. Lorsqu’on compose des outils pour en faire une solution complète, un problème apparaît : la gestion des numéros de version et des incompatibilités entre les composants de cette sollution. Aujourd’hui, si l’on prend la « pile ELKB/BELK », nous avons :
- ElasticSearch 2.3.x
- Logstash 2.3.x
- Kibana 4.5.x
- Beats 1.2.x composé de :
- Winlogbeat 1.2.x
- Filebeat 1.2.x
- Topbeat 1.2.x
- Packetbeat 1.2.x
- LibBeats 1.2.x
Comment s’assurer que tous les produits sont compatibles entre-eux? D’un point de vue technique, c’est compliqué : il faut gérer une matrice de compatibilité qui doit être fournie par l’éditeur. L’éditeur doit faire des tests en faisant varier les versions de chaque composant. Les mises à jour doivent être bien documentées pour éviter qu’un utilisateur perde des données. La matrice de compatibilité doit être claire et compréhensible, sans erreur d’interprétation possible.
D’un point de vue marketing, c’est compliqué aussi! Toute la communication doit aussi être mise en œuvre pour que les utilisateurs et les clients suivent (correctement!) la matrice de compatibilité. Lorsqu’un client ou un utilisateur mettra à jour un composant qui sera incompatible avec tous les autres, c’est l’image des développeurs et de l’entreprise qui va en pâtir par les retours sur les forums utilisateurs, les articles de blog négatifs, les présentations lors des événements communautaires (salons, forums) et les bugs ouverts. Et ces retours négatifs risquent d’être très nombreux : les outils sont jeunes et évoluent très vite et le succès est grandissant.
D’où l’idée d’Elastic de coordonner les numéros de version : désormais il y aura un produit « The Elastic Stack » dans une version donnée et intégrant tous les outils, chaque outil ayant la même version majeure. La première version de « The Elastic Stack » sera la prochaine version, la version 5.0.0 et intégrera tous les produits dans la version 5.0.0. Ce qui sera plus simple pour tout le monde : clients, utilisateurs mais aussi développeurs et ingénieurs support d’Elastic!
Refonte graphique
Pour communiquer plus efficacement sur « The Elastic stack », la charte graphique des outils a été refondue lentement. Dorénavant, il y a une unicité graphique entre les outils concernant les logos :

Auparavant, les logos pouvaient être très différents :
![]()
Première version disponible
La première version alpha de « The Elastic Stack » est disponible en version 5.0.0 alpha 1. Bienvenu à « The Elastic Stack » et merci à « la pile ELK » pour les services rendus.
Read MoreCompte-rendu du meeting Zabbix France du 5 Avril 2016
Mot de bienvenue d’Alexei Vladishev (Zabbix SIA CEO)

Les nouvelles fonctionnalités de Zabbix 3.0
- L’interface graphique (UI) qui n’avait pas évolué depuis longtemps fait peau neuve.

- L’amélioration de la sécurité avec le support du chiffrement sur l’ensemble des composants Zabbix.

- Il est possible de partager cartes, écrans et diaporamas avec d’autres utilisateurs ou groupes d’utilisateurs.

- L’apparition de nouvelles fonctions Timeleft (combien de temps avant d’être sous le trigger ?) et Forecast (quelle sera la valeur d’un item au bout d’un certain laps de temps ?).


- L’utilisation CPU par processus (individuel ou groupe).

- Les applications peuvent être créées via une règle de découverte bas niveau (Low Level Discovery).
- L’amélioration des performances (history cache, multiple escalators, amélioration du cache)
- La possibilité pour les items d’être déclenchés à des périodes précises façon crontab.



- Le nettoyage de la base de données (Housekeeper) peut être exécuté à la demande.
- Il est possible d’exécuter Zabbix en avant-plan.
- L’authentification SMTP pour l’envoi de courriels.

Recommandation
Le support des versions de Zabbix
Études de cas d’utilisation de Zabbix par Sergey SOROKIN (Business Development)
- Retour sur la supervision du système des noms de domaine de l’internet (ICANN).
- Un autre exemple d’un client, dont le nom n’a pas été cité, dans le domaine de la logistique qui nous parle d’amélioration de sa chaîne métier avec un outil de supervision.
Le futur de Zabbix, notamment la version 3.2 (Alexei VLADISHEV)
- La gestion avancée de supervision de fichier de log et remontée de trap
- De l’event correlation (dé-duplication, agrégation, tempête de messages, filtrage et masquage)
- De la modularité au niveau des composants Zabbix
Les avantages à utiliser les services professionnels de Zabbix (Sergey SOROKIN)
Cela tourne autour du Service avec :
- Installation, mise à jour
- Support
- Formation
- Création de modèle de supervision
- Assistance client (sur site ou à distance)
Présentation du réseau de professionnels Zabbix en France
Sergey SOROKIN a présenté les partenaires France de Zabbix.


![]()

Read More
Logstash 2.3.0 : forte amélioration des performances
Logstash est un outil de collecte, de traitement et de transport de données. Logstash est disponible en version 2.3.0 depuis le 30/03/2016 et cette nouvelle version apporte, en autres, une augmentation significative des performances.
Présentation rapide de Logstash
Logstash a pour but d’ingérer des logs (fichiers journaux des systèmes et applications) ou des messages (provenant de RabbitMQ par exemple), de les analyser (filtrer les messages inutiles, les découper, extraire l’information utile, les formater) puis de les stocker, généralement dans ElasticSearch pour être indexées. La force de Logstash est de pouvoir ingérer tout type de logs :
- des logs au format syslog : très répandus sur les systèmes GNU/Linux et Unix
- des logs en texte brut
- des logs Apache et Log4j
- des logs Windows Event Logs
- des messages au format JSON
- des messages passant par des files de messages (RabbitMQ, ZeroMQ)
- …
Bien entendu, vous pouvez étendre le système et faire ingérer vos propres formats. Une fois les messages ingérés, Logstash les filtre, prend des actions et/ou les formate pour les stocker dans ElasticSearch, MongoDB, Riak, …
Logstash évolue très rapidement et de nouvelles versions apportent souvent de nouveaux connecteurs, tant en entrée qu’en sortie.
Version 2.3.0 : forte amélioration des performances
La version 2.3.0 de Logstash est sortie le 30/03/2016 et cette version apporte une forte amélioration des performances. Elle se traduit par un traitement plus rapide des messages, une augmentation de la vitesse de traitement jusqu’à, dans certains cas, 79%. Cette augmentation est due à la ré-écriture en pure Java d’un composant de l’application, préalablement écrit en Ruby. L’équipe de développement de Logstash a fait des tests et a publié les résultats dont voici un résumé :
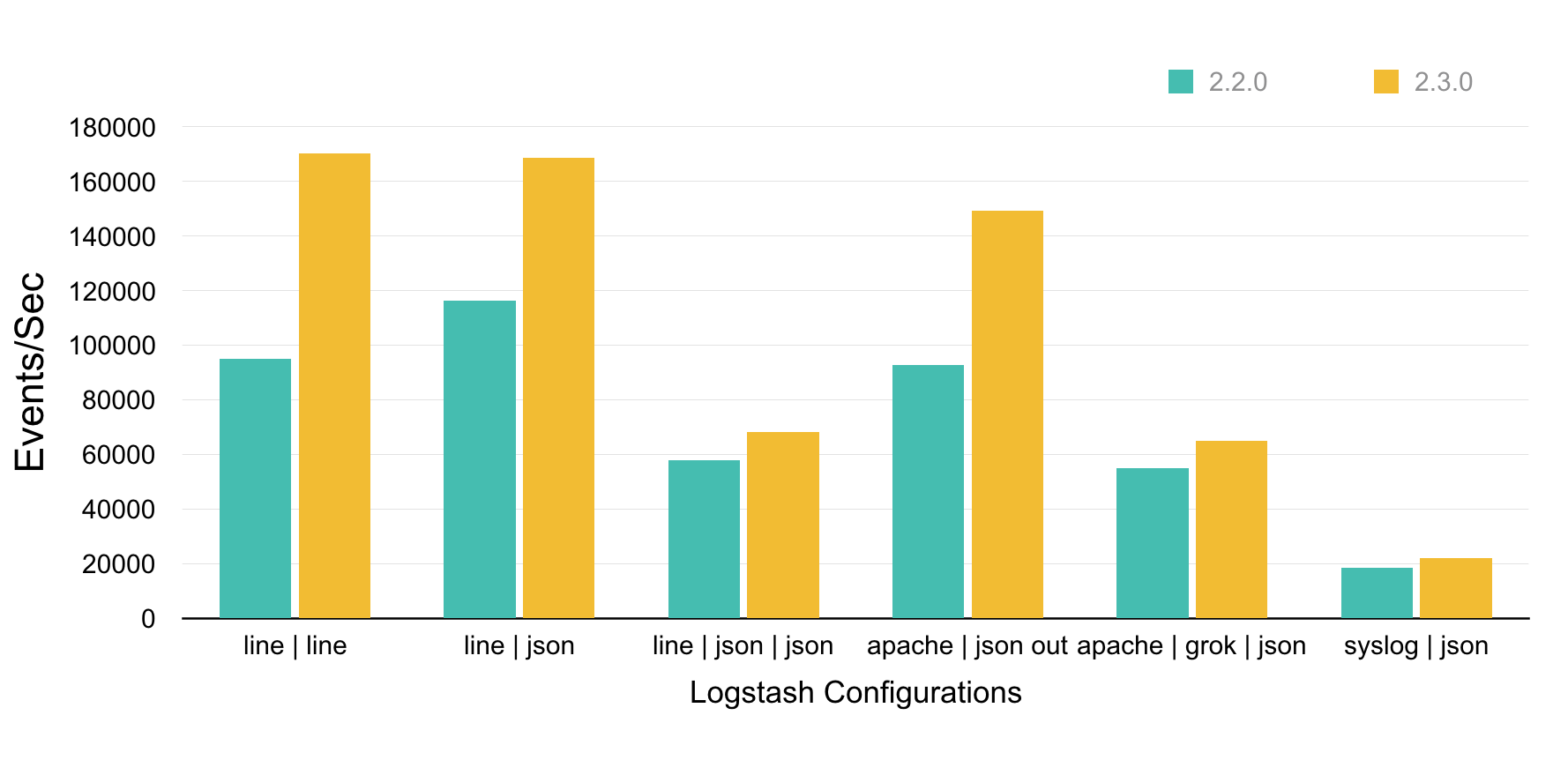
Lostash 2.3.0 : améliorations des performances diagramme
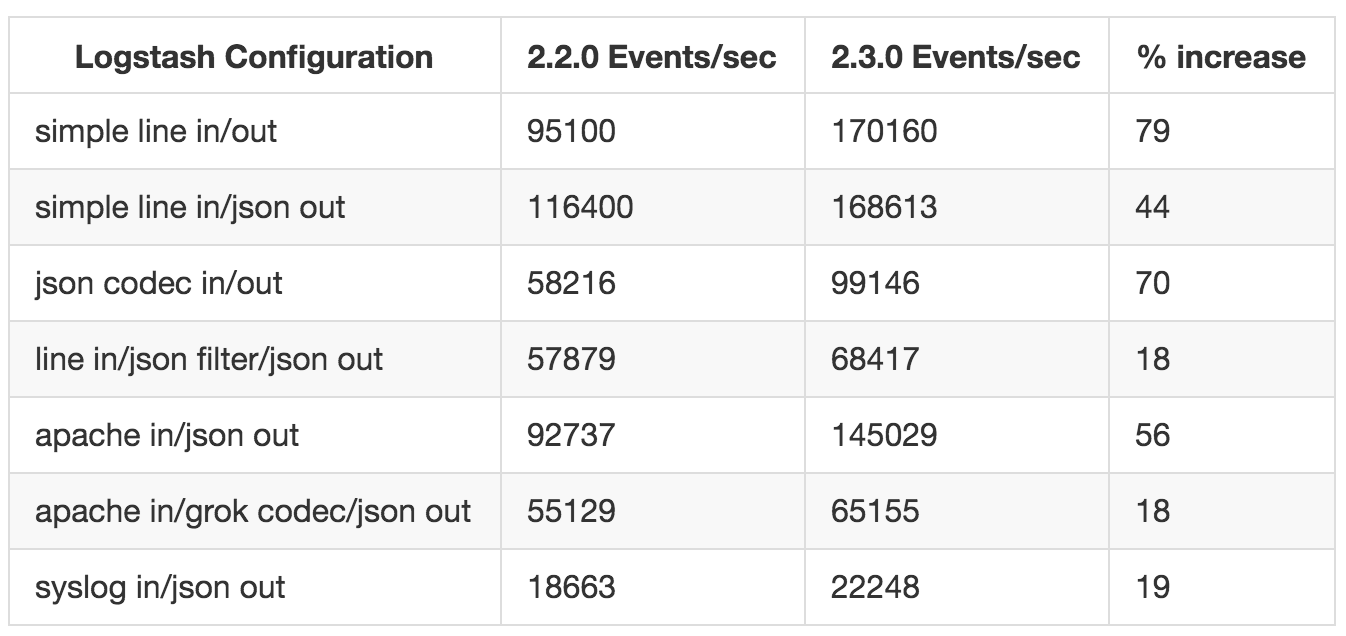
Lostash 2.3.0 améliorations des performances tableau
Relecture à chaud de la configuration
Cette version 2.3.0 introduit la relecture de la configuration à chaud. Cela permet de ne pas avoir à redémarrer le service lorsqu’un paramètre de la configuration est modifié : en effet, Logstash va vérifier régulièrement (toutes les 3 secondes, par défaut) si une modification a été faite sur les fichiers de configuration. Dans ce cas, il va relire les fichiers et adapter son comportement. Pratique lorsqu’on développe mais aussi lorsque la configuration est modifiée par des outils externes, en fonction de règles dynamiques : cela évite de redémarrer Logstash par un script.
Pour activer la relecture à chaud, il faut passer l’option --auto-reload lors du démarrage de Logstash.
Si jamais vous souhaitez maîtriser le moment où LogStash doit relire la configuration, il vous suffit de ne pas passer l’option --auto-reload et d’envoyer le signal SIGHUP au processus.
Netdata : Real-Time performance monitoring
Le monitoring est l’un des enjeux actuels des outils de supervision (ici, le terme supervision est pris dans son sens le plus large possible). Pour rappel, le monitoring consiste à récolter des données numériques et tracer leur évolution dans le temps sur des graphiques. Ceci est pour le cas d’utilisation le plus simple. Cependant, le cas d’utilisation actuel est plus complexe :
- prédire quand l’indicateur mesuré dépassera une valeur cible afin de pouvoir anticiper ;
- combiner les indicateurs entre eux ;
- faire des calculs sur les valeurs afin d’en tirer une information consolidée plus intéressante ;
- analyser automatiquement les valeurs pour éviter d’alerter inutilement ;
- stocker cette masse d’informations ;
- être performant ;
- disposer de fonctions graphiques permettant une utilisabilité optimale ;
- être visuellement agréable ;
- …
Ceci vaut notamment pour les infrastructures disposant de nombreux équipements. Est-ce que cela est nécessaire pour tout le monde? C’est oublié la maxime less is more : en faire moins, retirer tout ce qui n’est pas utile pour extraire l’intérêt premier d’un outil. Netdata est un outil libre (GPLv3) de ce type. Son intérêt est qu’il convient parfaitement à des parcs informatiques de quelques dizaines de serveurs.
Netdata, le monitoring pour les « petits » parcs informatiques
Netdata convient parfaitement aux petits parcs informatiques. Petit, ici, n’est pas péjoratif mais réaliste : est-il nécessaire de passer plusieurs jours à installer puis configurer un outil de monitoring en essayant de comprendre les différentes fonctions de consolidations et leurs différentes subtilités lorsqu’on est en équipe réduite, avec un budget et un temps limités ? Non, évidemment ! Netdata permet de disposer d’un outil relativement simple à installer et configurer et disposant de fonctionnalités intéressantes.
Netdata, le monitoring en temps-réel
Netdata n’est pas forcément dédié aux petits parcs informatiques. Il convient parfaitement aux grands parcs informatiques : dans ceux-ci, généralement, un outil de gestion de configuration est utilisé et peut permettre de déployer un logiciel et sa configuration sur l’ensemble des serveurs GNU/Linux. La philosophie de Netdata est le monitoring en temps-réel. Cela signifie que vous ne disposez pas d’une centralisation de toutes les informations mais d’une information en temps-réel sur chaque équipement. Vous devez vous connecter sur chaque équipement pour visualiser ses informations.
Il est à noter que la durée de rétention est paramétrable mais l’outil n’est pas conçu pour stocker les informations sur une longue période de temps. Augmenter de manière significative cette durée de rétention peut faire exploser la mémoire du serveur ou influer négativement sur ses performances.
Installation sur chaque équipement monitoré
Netdata s’installe sur chaque serveur monitoré. L’installation de Netdata nécessite une compilation des outils. Pour le moment, la procédure est documentée pour Debian, Ubuntu, RedHat, CentOs et ArchLinux. À la vue de celle-ci, elle peut aussi être adaptée pour d’autres distributions GNU/Linux et, pourquoi pas, pour les BSD voire les Unix propriétaires, si les dépendances sont disponibles. D’ailleurs, Netdata indique que l’outil a été testé avec succès sur Fedora et Gentoo.
Netdata ne gère pas le monde Windows pour le moment. Cela ne semble pas être prévu et nécessiterait une réécriture quasi-complète de l’outil.
Auto-détection et dashboard par défaut
Lors de son démarrage, Netdata va détecter automatiquement certaines informations et collecter les données. Il n’est pas nécessaire de déclarer toutes les interfaces réseaux, tous les disques, le nombre de CPU, la taille de la mémoire vive, … Il va aussi détecter automatiquement les processus « courants » (cron, ntp, named, ssh, nfs, nginx, …) et les grouper par « fonction » pour tracer la consommation CPU de chacun.
Par contre, il ne va pas détecter quelles sont les applications installées et activer automatiquement le « plugin » nécessaire. Par exemple, si vous souhaitez disposer d’indicateurs spécifiques sur MySQL ou NGinx, vous devrez activer le « plugin » et le configurer.
Un dashboard par défaut est proposé. Celui-ci contient tous les indicateurs. La configuration est complète, voire trop complète mais la configuration par défaut convient parfaitement.
Interface attrayante
L’interface est plutôt attrayante et les graphiques ressemblent, par certains aspects (couleurs, design, légende, …), à Grafana. Vous pouvez survoler les graphiques pour obtenir les valeurs mesurées. Sur des graphiques avec plusieurs valeurs tracées, il est possible de choisir quel élément sera tracé en cliquant sur la légende pour les afficher/cacher.
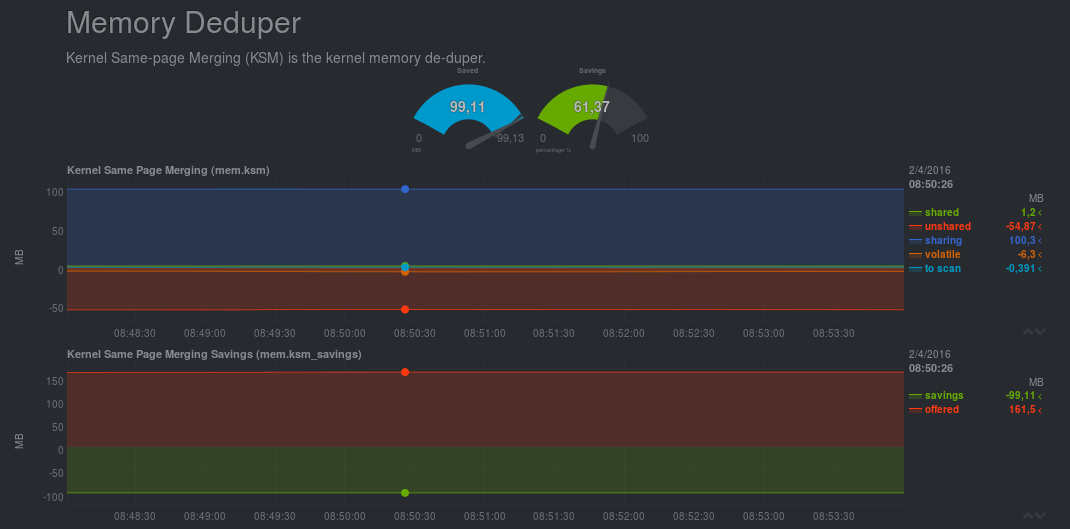
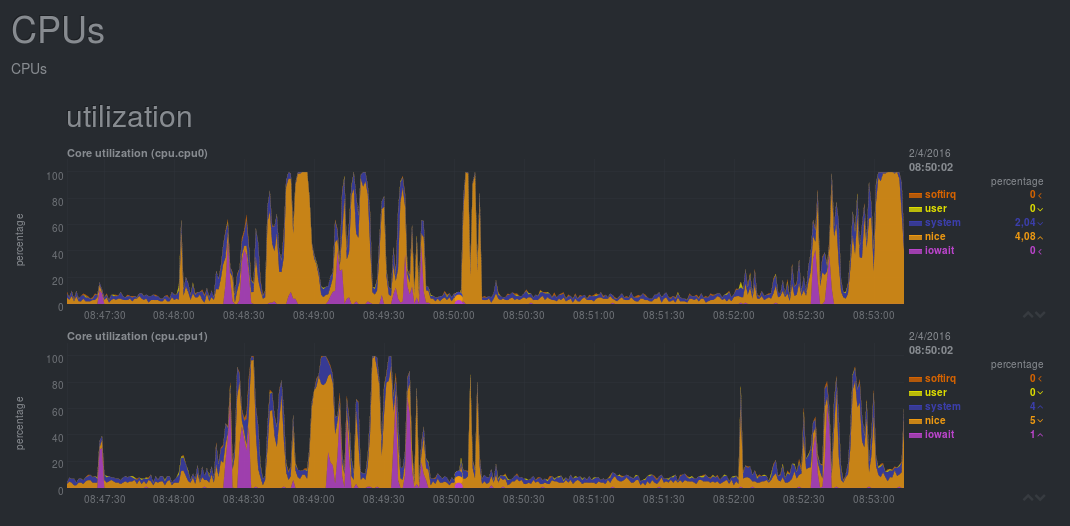
La première partie de l’écran est composé d’indicateurs globaux du système comme la moyenne des taux d’occupation des CPU, les écritures disques, le taux d’occupation de la swap, …
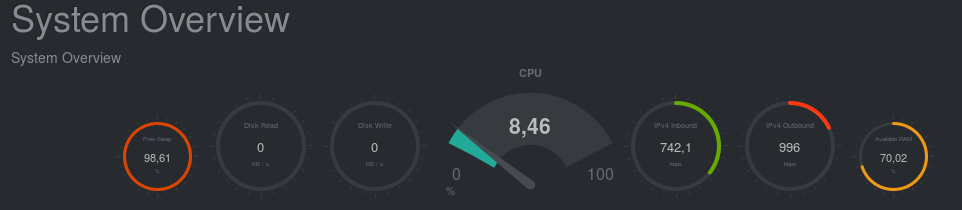
Netdata : overview
Pour naviguer dans les indicateurs disponibles, le menu se trouve à droite de l’écran et est composé en deux niveaux. Le premier niveau se replie automatiquement pour éviter de prendre trop de place et il est en position fixe, donc toujours visible : très pratique pour naviguer efficacement dans les indicateurs. Certains outils de supervision plus mainstream devraient s’en inspirer (suivez mon regard 😉 ).

Il est possible de revenir dans le passé, en cliquant avec la souris sur le graphique, en maintenant le click puis en se déplaçant vers la gauche. C’est le même mouvement que pour se déplacer dans un outil en ligne de cartographie comme Google Maps par exemple.
L’interface permet de zoomer dans les graphiques, en enfonçant et en maintenant enfoncée la touche SHIFT du clavier puis sélectionnant la zone sur laquelle vous souhaitez zoomer à l’aide de la souris et en relâchant. Lorsque le bouton de la souris est relâché, tous les autres graphiques sont mis à jour à la même période : pratique.
Il est possible de zoomer dans le graphique différemment. Pour cela, il faut toujours enfoncer et maintenir la touche SHIFT du clavier, placer le pointeur de la souris sur un graphique et utiliser la roulette de la souris pour zoomer ou dé-zoomer. Problème : cette fonction n’est disponible que sur Chrome, pas sur Firefox ni sur IE/Edge. Aucune information n’est disponible pour les autres navigateurs (Safari par exemple) et n’en ayant aucun à ma disposition, je ne peux le vérifier.
Pour revenir à un « état normal » de l’interface c’est à dire à la visualisation temps-réel et un rafraîchissement automatique des graphiques, il suffit de double-cliquer sur un graphique.
Limites
Comme tout outil, Netdata a ses limites. Il est bon de connaître les points forts d’un outil mais aussi ses limites pour vérifier si celui-ci correspond à vos besoins.
Netdata est limité au monde GNU/Linux. Si votre parc informatique est composé de serveurs Windows, vous ne pourrez pas l’installer sur ceux-ci. Il est peut-être possible qu’il fonctionne sur *BSD, mais vous ne disposerez pas de tous les indicateurs collectés. Cela peut-être bloquant pour vous (ou pas!).
Netdata nécessite d’être installé sur tous les serveurs, contrairement à certains outils qui requiert uniquement l’installation d’un agent spécifique ou l’activation de SNMP. Cela peut-être très gênant sur les serveurs exposés sur Internet : il faut bien vérifier les règles de sécurité pour s’assurer qu’un potentiel attaquant n’aura pas d’accès à l’interface de Netdata et voir en temps réel quelles sont les meilleures actions pour « DOSer » votre serveur. Cependant, l’installation de Netdata sur chaque serveur se justifie dans le sens où l’outil a pour but de monitorer « en temps-réel » les serveurs.
L’intégration de Firefox et de IE/Edge n’est pas parfaite : il est impossible de faire un zoom arrière sur ses navigateurs. Cela n’est peut-être pas de la responsabilité des développeurs de Netdata car Firefox utilise SHIFT+mollette de la souris pour naviguer dans l’historique. Il est presque obligatoire d’utiliser Google Chrome pour utiliser Netdata : dommage!
Il manque un raccourci sous forme de boîte de sélection qui afficherait « la dernière heure », « les 3 dernières heures », … et qui permettrait de choisir la durée d’affichage par défaut.
La documentation est un peu fouillis : il est difficile de s’y retrouver lorsque l’on cherche un sujet précis. Elle est aussi incomplète sur certains sujets.
Read More